Semagrow allows both minimal and extensive configuration and can make the most out of whatever you can provide
Minimal configuration
As a bare minimum, one must declare the remote endpoints that Semagrow federates. These are specified in RDF using the Turtle format. By default, Semagrow looks at /etc/default/semagrow/metadata.ttl to find information about its federation. A metadata.ttl can be as minimal as:
The configuration shown above uses the VoID vocabulary to define a federation of DBPedia and the Nobel prize laureates dataset without providing any further details. A fuller VoID description would also provide information about the properties and classes used in each dataset. Such information is exploited by Semagrow in order to formulate a finer-grained query execution plan that is aware of which endpoints should be contacted in order to get relevant triples.
Many public endpoints publish VoID descriptions. See, for example, http://data.nobelprize.org/.well-known/void for the description of the Nobel dataset. These descriptions can be downloaded and aggregated into a Semagrow configuration file. Our choice of Turtle for serializing the RDF metadata that configures Semagrow is in fact motivated by the ease of combining Turtle files by simple concatenation.
The metadata.ttl file can be inspected and modified with any text editor or RDF editor. The ELEON editor is such an RDF editor, specifically adapted to editing Semagrow metadata. You can find a detailed ELEON User Guide here.
Instance-level metadata
Besides the schema-level information descussed above, Semagrow can also take advantage of statistics about the entities described by a dataset and the relations between them, as well as about the linkes across datasets. Such statistics are used by the Semagrow query execution planner in order to optimize query execution.
The VoID vocabulary provides properties regarding the number of triples and distinct entities contained in a dataset. Semagrow can also exploit even more detailed information represented in our Sevod vocabulary that extends VoID with statistical information akin to database histograms.
However, statistical VoID properties and, even more so, Sevod properties are not used by the descriptions actually published by the dataset providers. Such detailed descriptions can be generated by Semagrow deployment administrators using either of the following tools:
sevod-scraper scrapes Sevod histograms from RDF dumps
STRHist estimates Sevod histograms by generalizing the results obtained by a query workload
STRHist is one of the most ambitious aspects of Semagrow, as it aims at the efficient federation of endpoints for which neither a dump nor detailed metadata are published, and without imposing a query workload solely for the purpose of estimating histograms: STRHist gradually improves the estimation of what data is behind an endpoint by observing the results of a client query workload.
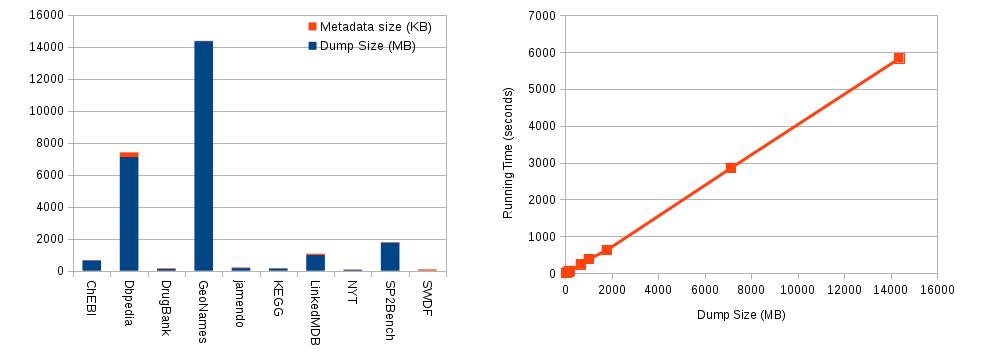
The time it takes for sevod-scraper to construct a detailed metadata file out of an RDF dumps is proportional to the size of the dump itself. Detailed measurements of the size over time is depicted in the following line chart.